
As health care technology management professionals, it is incumbent upon us to keep an eye on the trends in technology. Especially in IT, as things are rapidly changing and existing infrastructures become out of date quickly. For the biomedical and clinical engineering side of health care technology management, maybe all that is needed is an ear to the ground. However, no one likes to get caught flat-footed or be put into a position where they suddenly have to come up to speed to deal with an unexpected technological challenge. Which brings us to the reason for this column—to provide a peek around the corner to see what’s coming in health care IT to make sure you have a grasp of key issues.

Analyzing all the collected data in health care can lead to innovation, spotting trends, preventing diseases, and analyzing the workforce.
That’s why a look at one of the (literally) biggest trends in IT is worthwhile. Known as “big data,” it is somewhat officially defined as so much data that it becomes difficult and unwieldy for current IT systems to effectively handle. We have been hard at collecting data for at least 25 years, or at about the beginning of the PC boom. The other assumption behind the words “big data” is that you are going to do something with it. Analyzing that collected data can lead to innovation, spotting business trends, preventing diseases, combating crime, as well as merchandising analytics, price optimization, and analyzing the workforce, for example. Some of the analytical results are amazing. Consider some of the big data research and analytics in health care: Causal modeling using network ensemble simulations of genetic and gene expression data predicts genes involved in rheumatoid arthritis. Also, the potential of biologic network models in understanding the etiopathogenesis of ovarian cancer.
Advance forward to customized care 2020: How medical sequencing and network biology will enable personalized medicine; achieving confidence in mechanisms for drug discovery and development; a systems biology dynamical model of mammalian G1 cell cycle progression; an integrated approach for inference and mechanistic modeling for advancing drug development; systems biology for cancer; the statistical mechanics of complex signaling networks—nerve growth factor signaling; and data-driven computer simulation of human cancer cells. And that is the very tiny tip of the iceberg. Just how much data are we talking about? What are the opportunities? Why should we care about all this?
How Much Data?
I think it makes sense to keep our fingers on the pulse of big data in health care for two main reasons. One is the immediate effect it has on systems needed to support, store, manage, move, sort, and calculate the data. Big data might mean a couple of hundred gigabytes (GBs) to a few terabytes (TBs) at one facility. I have two 1TB external hard drives myself—though they are certainly not full (yet). Other facilities might only start to get challenged at a couple of hundred TBs and then be forced to consider new data management and storage choices to grow from there.
The really big data collectors make that pale in comparison. Take the Sloan Digital Sky Survey (SDSS) telescope that adds around 200 GB to its pile every night (~73TB per year)—and it began collecting data in 2000. They say that in the first few weeks of operation, it amassed more data than in the entire history of astronomy. When the Large Synoptic Survey Telescope comes online in 2016 (successor to SDSS), it will acquire as much data that SDSS has—every 5 days. The four main detectors at the Large Hadron Collider (a particle accelerator) produced 13 petabytes of data in 2010—or 13,000 TBs. Walmart processes a million customer transactions every hour and incorporates it into its 2.5 petabytes of data. That is 167 times the information contained in all the books in the US Library of Congress!
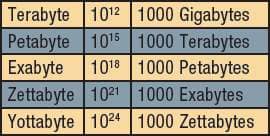
In comparison, estimates are that US health care reached 150 exabytes (150,000 petabytes) last year. Your data is in there, somewhere. The petascale IT systems of today will evolve into yottascales in the future (see sidebar, next column, for relative size info). It is hard to imagine.
What’s the Opportunity? Or—Other Big Numbers
The second reason to consider big data concepts is the $2.6 trillion health care market of today. It needs new efficiencies to not only manage and reduce costs, but also to improve health care overall. We cannot continue with current methods and cost models. There are many that believe big data can help us to understand what’s going on. Thomson Reuters says that there is an estimated $600 to $850 billion wasted—in that they are expenditures that fail to improve patient outcomes.1 Areas for waste include things like medical errors, criminal fraud, and unwarranted use of health services, administrative inefficiencies, and lack of preventive care.
Having all this data coupled with the technical ability to move it around and analyze it is just one piece of the massive puzzle. Proper modeling of the data and sharing health care data among organizations can drive efficiencies and improve patient outcomes. McKinsey Global Health Institute thinks that $200 to $300 billion can be saved through the use of big data analytics, or about half of what Reuters estimates is waste.2The government is also interested in health care big data. Since it pays somewhere around 40% of all health care costs, government improving data management techniques will help drive costs out and improve patient outcomes substantially. The FDA, CDC, and NIH already study data to help prevent disease outbreaks and to survey new drugs on the market. By using big data after treatment, they can track changes in behavior and become better educated for positive patient outcomes.
Can Technology Deliver?
Big data requires new technologies to efficiently process it within a reasonable elapsed time. It’s getting better. What took 10 years to decode the human genome can now be achieved in 1 week. Oracle, Microsoft, IBM, and others have spent more than $15 billion specializing in data management and analytics. This industry is estimated at $100 billion and growing at 10%, or twice that of the software business as a whole.
Consider that one of the big data technologies is massively parallel processing (MPP) databases. To get a perspective, this software is essentially a relational database running on 10, 100, or even 1,000 servers. It gets tough to run on a laptop or a desktop statistical package!
In addition, big data analyzers typically shy away from shared storage. They prefer to work with direct-attached storage (DAS). DAS has a variety of forms, from solid state disk (SSD) to high-capacity SATA disk buried inside parallel processing clients or servers. Many of the people involved in the analytics prefer to have the data ready in memory, rather than having to go fetch it in pieces and analyze bits, then collate the analyses—it can get complicated quickly. The idea is that shared storage architectures are slow, complex, and expensive. Big data analytics systems tend to lean on system performance to avoid working with stale data and commodity infrastructures that are easy to source with low cost.
Real-time or near-real-time data delivery is one of the main tenets of big data analytics. Latency is a bad word and must be avoided. Data should be handy and loaded in memory. Data on a spinning disk on the network is too slow and undependable. Besides, all the extra hardware costs too much. These are some of the hardware considerations that big data will drive.
Bottom Line
To make a difference with big data, we will need to produce better evidence via analytics faster and on a larger scale. That means, in part, shared data that is reliable, clean, and in a common format. Without meaningful evidence, we cannot tell what works where. We need meaningful evidence to reduce costs and obtain meaningful improvements in patient outcomes. The dreams of cost savings and desirous effects on health care are real—but so is the work to get us there.
The era of big data in health care has arrived. With the government pushing the electronic health record, more data than ever will be made available at faster rates as systems settle. A recent McKinsey report called big data “the next frontier for innovation, competition, and productivity.”2Maybe a quote from the International Institute of Analytics sums it up best: “Analytics asset management will emerge as a major challenge this year. Analytics data, models, findings, and recommendations are corporate assets, and these assets require continuous management in order to deliver a stable source of financial return for firms.” And that’s where technology management comes in!
Jeff Kabachinski, MS-T, BS-ETE, MCNE, has more than 20 years of experience as an organizational development and training professional. He is the director of technical development for Aramark Healthcare Technologies in Charlotte, NC. For more information, contact .
References
- Kelley R. Where can $700 billion in waste be cut annually from the US healthcare system? Thomson Reuters White Paper, October 2009. www.ncrponline.org/PDFs/2009/Thomson_Reuters_White_Paper_on_Healthcare_Waste.pdf. Accessed April 12, 2012.
- Manyika J, Chui M, Brown B, et al. Big data: The next frontier for innovation, competition, and productivity. McKinsey Global Institute Report. May 2011. www.mckinsey.com/Insights/MGI/Research/Technology_and_Innovation/Big_data_The_next_frontier_for_innovation. Accessed April 12, 2012.

